Initial Exploration
Watch https://www.wolfram.com/broadcast/video.php?c=377&p=2&v=1258
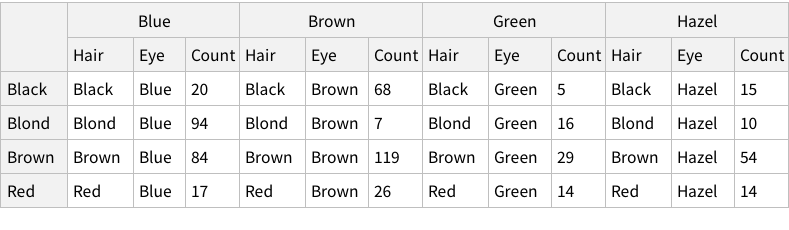
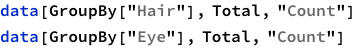
Given the structure so far, we need to figure out a way to have named rows, nested with further named rows. Like so: {“Brown Eye”->{“Black Hair”->4, “Blond Hair”->10}, “Blue Eye”->...}
Not sure if this should be done at import time, or as the next step after import.
Importing Data
How should it look like?
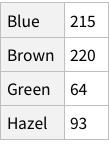
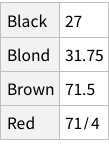
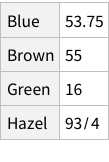
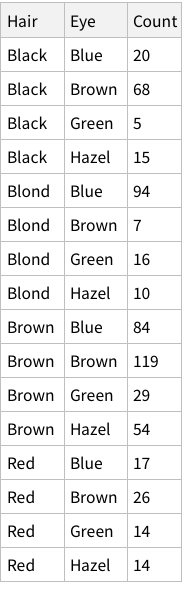
We want our Hair + Eye colour data to be structured “nicely” before we start doing analysis. What is this “nice” structure?
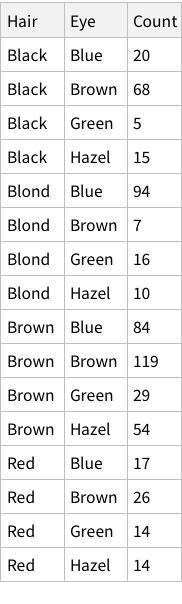
If imported simply, this is what it looks like:

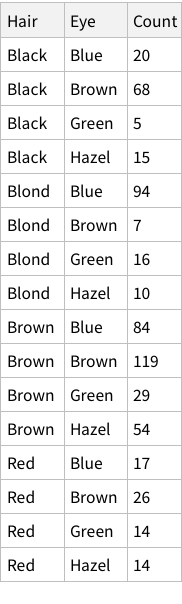
This structure is not bad, it correctly figures out that the first row of the CSV is column names. But is this how we want things to be? Could we have more structure to it?
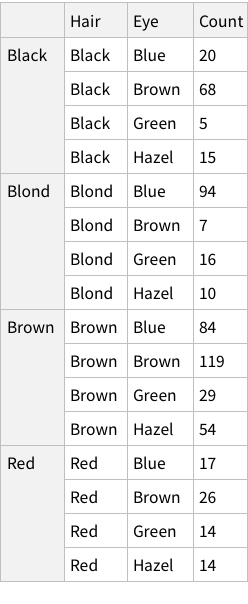
One approach can be to add some named rows. For example, we can imagine that the actual data point in the entire dataset is the `Count` column, rest are just names! Which means, we can have rows of rows.
Let’s try. What does the structure look like?
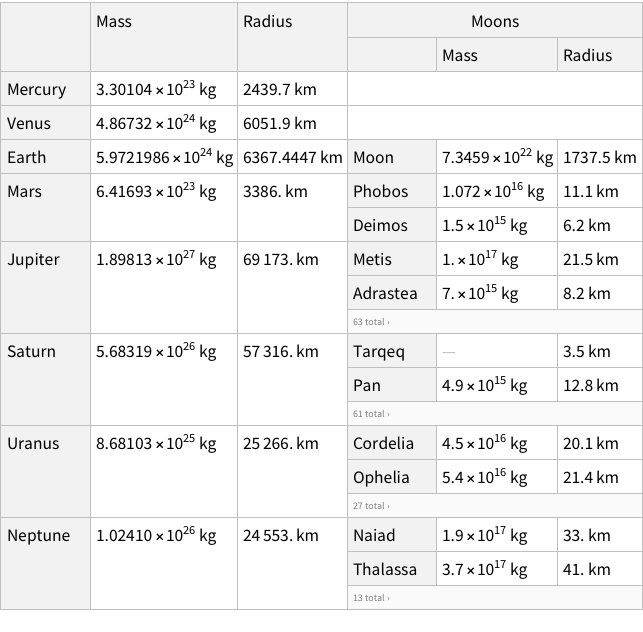
Okay, now that we know how data is represented, we can try manually creating a row or two for our data.
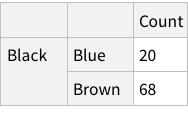
Does this look good? We don’t have column names for Hair and Eye, but we do for Count. Is that normal? If you look at the Moons in the planet dataset, you can see that the names of of moons are not column-named, but their properties are column-named. Which is analogous to what we have for our dataset as well.
Let’s finalise on this structure for now, and find out how to convert the imported data.
Structuring Imported Dataset
So far, I have not found any simple way to morph the dataset. The important note found so far is that we cannot modify existing Dataset, but instead have to create new Dataset with the structure we want. What this means, is that we will have to define Column/Row structure and select proper Count columns for the new Dataset definition.
This manual approach is too much hassle. And figuring out “script-like” way to change the structure is not attractive right now.
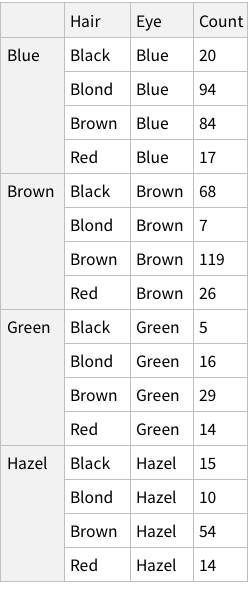
Hence, we will try to roll with what we have and see what happens when we try doing operations on the data.
References
https://www.wolfram.com/broadcast/video.php?c=377&p=2&v=1258
https://www.youtube.com/watch?v=XN8Y177doEE
https://www.wolfram.com/wolfram-u/courses/data-science/becoming-a-data-curator-dat906/
Basic Analysis
Exercises from 4.6
Exercise 4.1
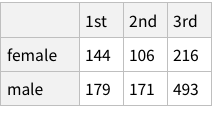
The eye-color hair-color data is frequencies of eye and hair color for males and females. Run the (some, we are going to ignore them) R code.
In your write-up, include each line above and its results. Explain what each line does (in a bit more detail than the inline comments). Extend above commands by also computing the probabilities of the hair colors given brown eyes, and the probabilities of the eye colors given Brown hair.
First, let’s import the data and show it.

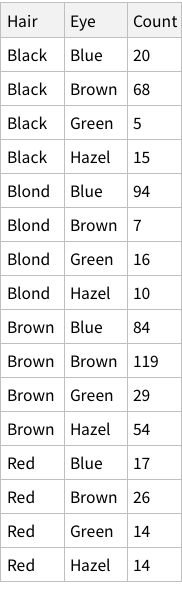
Run equivalent of:

Funnily enough, the R code given by the book loads the CSV, generates Male/Female split, and then store in the variable “HairEyeColor”. The “sum” application then gives the data we have got already!
Next line is dividing each cell by the total.
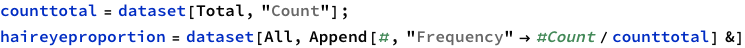
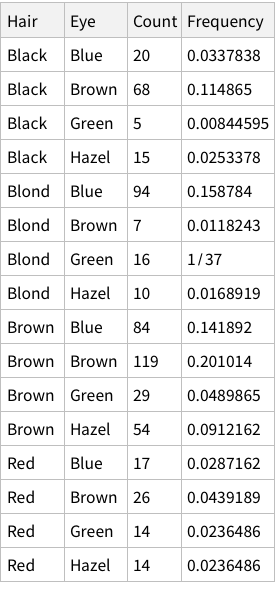
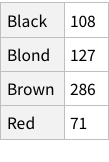
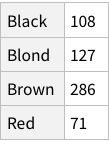
To find total counts of each hair-color:
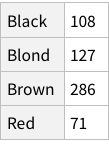
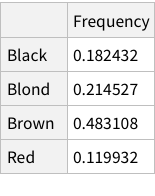
Like we added the Frequency column above for all rows, do the same but for the grouped data:
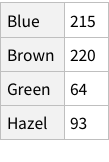
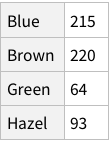
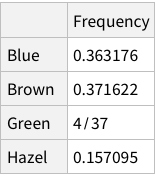
Same operations now for eye colors:

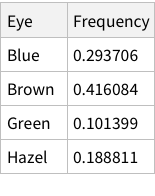
Calculate conditional probability of Hair, given Blue eye color (table 4.2):
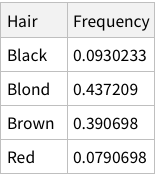
Calculate conditional probability of hair colors given brown eyes:
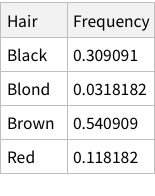
Calculate conditional probability of eye colors given brown hair:
Let’s now try to understand, verbally, what the exercise was about.
We were given raw counts for hair+eye colour combos. Just like one of the section in the chapter, we wanted to get to finding out conditional probabilities.
To get to conditional probabilities, we needed some basic information derived first:
Proportions of each hair+eye colour combo
Proportions of each hair colour
Proportions of each eye colour
When we calculate hair+eye proportions, we are calculating joint probabilities. For example, the probability of finding someone with both Brown eyes and Black hair is 0.11 i.e. 11% and so on.
When we calculate the proportions of only hair or only eye colours, we are measuring probability of finding, for example, a person with black hair; a person with blue eyes and so on. For example, the probability of finding a person with Black hair is 0.18 / 18%; a person with Brown eyes is 0.37 / 37%
Finally, we can use the derived information to calculate conditional probabilities. To calculate the probability of a person having Hazel eyes, given we know that the person has Blond hair we need to divide independent probability by marginal probability. So, for the specific case, the calculation is: 0.0168919/0.214527 = 0.078 (~7%)
Thus ends a successful Exercise 4.1! Notice how the entire exercise was about calculating proportions in various ways and it did not feel the way it did when reading the section of the book.
Exercise 4.2
Modify the coin flipping program in Section 4.5 to simulate a biased coin that has p(H)=0.8. Change the height of the reference line in the plot to match p(H). Comment your code.
Okay, this is more involved since it is mainly about R code. We will have to first write code to simulate coin flips, then make the coin flips biased.
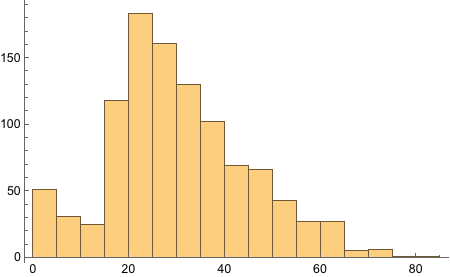
Alright, let’s think about this. The R code uses `sample` function that takes probability values with with to take the samples. We need something similar in Mathematica. But what is our real goal? We want to flip a coin - [H,T]. And when it is flipped we want to specify how biased the coin is. Having flipped the coin N times, we want to plot the running proportion of H and know the end proportion.
First, we have RandomVariate function that can take some distribution. The one we might find useful is DiscreteUniformDistribution. Let’s try.
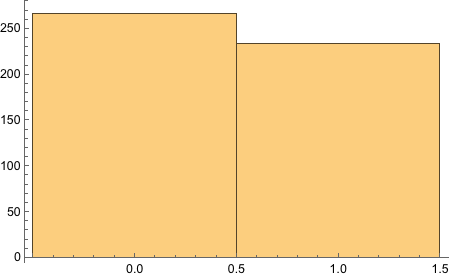
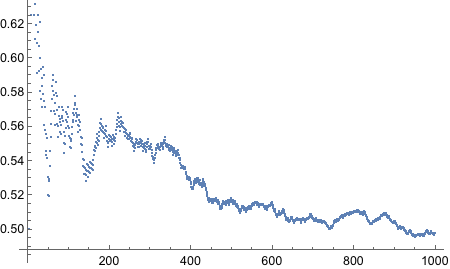
There, we got the end proportions of the fair die after 500 tosses.
Still no idea how to get “running proportion”! FoldList works, but does not give access to current index of the list. MapIndex does not keep track of previous elements. Looks like we will have to write our own function. Not fun, I must say.
Stolen the following code from https://mathematica.stackexchange.com/questions/190503/how-to-make-foldlistindexed-ie-foldlist-with-an-index-or-iterator
This approach may not be the thing we want. What we want is a list: and so on.
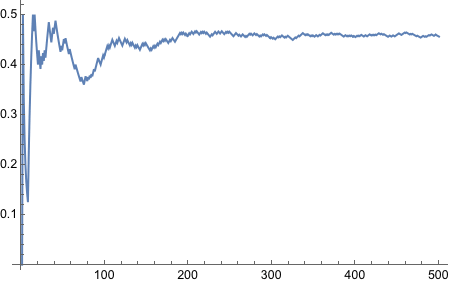
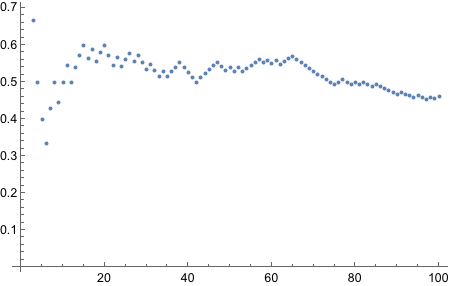
Well what do we have here! It worked! It is the ugliest way to do things because it is not functional, but it got the job done. We will refine this somehow.
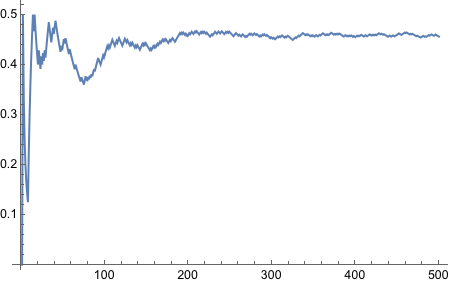
There we go, it is now functional - nice and neat.
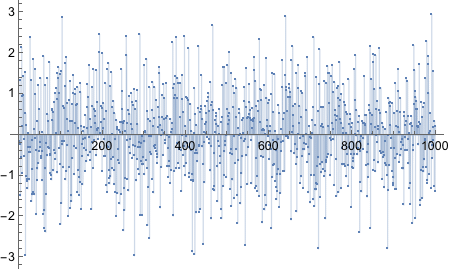
Now we need to bias the coin such that the probability of Heads is 0.8.
There’s BernoulliDistribution which “represents a Bernoulli distribution with probability parameter p. Also known as the coin toss distribution or Bernoulli trial”. Since it literally says “coin toss” in there, we should try it out.

Yes! Looks good! Let’s plot!
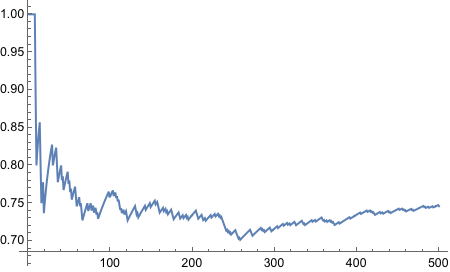
And thus concludes the exercise!
Exercise 4.4
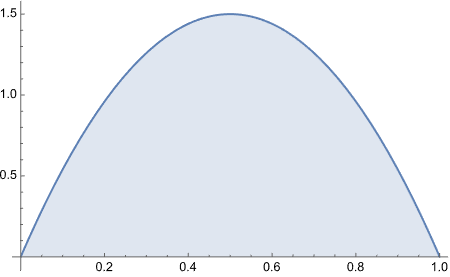
Consider a spinner with a [0,1] scale on its circumference. Suppose that the spinner is slanted or magnetized or bent in some way such that it is biased, and its probability density function is p(x) = 6x(1-x) over the interval x ∈ [0,1].
Adapt the program IntegralOfDensity.R to plot this density function and approximate its integral. Comment your code. Be careful to consider values of x only in the interval [0,1]. Hint: You can omit the first couple of lines regarding meanval and sdval, because those parameter values pertain only to the normal distribution. Then set xlow=0 and xhigh=1, and set dx to some small value.
Derive the exact integral using calculus.
Does this function satisfy equation 4.3?
From inspecting the graph, what is the maximal values of p(x)?
Here is the R code from the file:
source("DBDA2E-utilities.R")
# Graph of normal probability density function, with comb of intervals.
meanval = 0.0 # Specify mean of distribution.
sdval = 0.2 # Specify standard deviation of distribution.
xlow = meanval - 3.5*sdval # Specify low end of x-axis.
xhigh = meanval + 3.5*sdval # Specify high end of x-axis.
dx = sdval/10 # Specify interval width on x-axis
# Specify comb of points along the x axis:
x = seq( from = xlow , to = xhigh , by = dx )
# Compute y values, i.e., probability density at each value of x:
y = ( 1/(sdval*sqrt(2*pi)) ) * exp( -.5 * ((x-meanval)/sdval)^2 )
# Plot the function. "plot" draws the intervals. "lines" draws the bell curve.
openGraph(width=7,height=5)
plot( x , y , type="h" , lwd=1 , cex.axis=1.5, xlab="x" , ylab="p(x)", cex.lab=1.5, main="Normal Probability Density" , cex.main=1.5 )
lines( x , y , lwd=3 , col="skyblue" )
# Approximate the integral as the sum of width * height for each interval.
area = sum( dx * y )
# Display info in the graph.
text( meanval-sdval , .9*max(y) , bquote( paste(mu ," = " ,.(meanval)) ), adj=c(1,.5) , cex=1.5 )
text( meanval-sdval , .75*max(y) , bquote( paste(sigma ," = " ,.(sdval)) ), adj=c(1,.5) , cex=1.5 )
text( meanval+sdval , .9*max(y) , bquote( paste(Delta , "x = " ,.(dx)) ), adj=c(0,.5) , cex=1.5 )
text( meanval+sdval , .75*max(y) ,bquote( sum({},x,{}) *" "* Delta *"x p(x) = "* .(signif(area,3)) ) ,adj=c(0,.5) , cex=1.5 )
# Save the plot to an EPS file.
saveGraph( file = "IntegralOfDensity" , type="eps" )
That’s a lot of code just to display graphs. Disregard those lines, and we are left with a few important lines:
# Specify comb of points along the x axis:
x = seq( from = xlow , to = xhigh , by = dx )
# Compute y values, i.e., probability density at each value of x:
y = ( 1/(sdval*sqrt(2*pi)) ) * exp( -.5 * ((x-meanval)/sdval)^2 )
# Approximate the integral as the sum of width * height for each interval.
area = sum( dx * y )
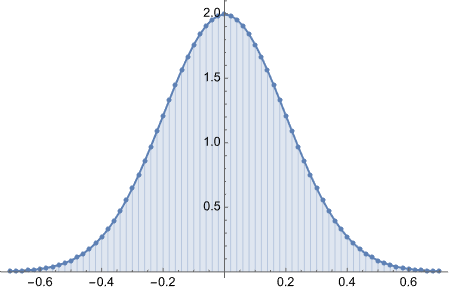
Fairly straight forward. Initially I thought we are going to use NormalDistribution function, but no. This is just calculating values of “probability density” in a range (0 to 1) with some interval and plots the values. Can we find some excuse to use NormalDistribution?
Anyway, here we go:

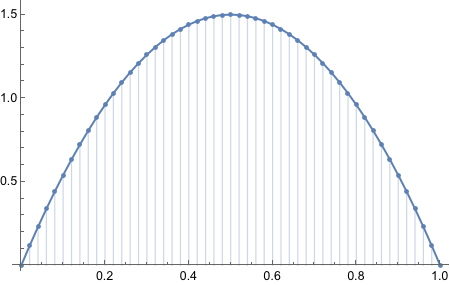
I am curious how the plot looked liked with the original equation.

In[296]:=
integrate 6x(1-x) from 0 to 1
Thus concludes the exercise.
However, there’s something more we can try. That is to see if we can find more Mathematica-like ways of doing this.
Thinking about it, we are given a probability distribution function 6x(1-x). And all we want is to see how it will behave for different values of the variable x. There is one potential function we can try.
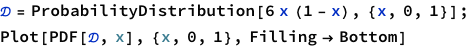
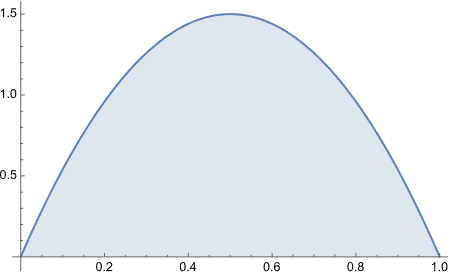
Ah! Look what we got here! Perfect.
To get area under the curve we do CDF[a] - CDF[b]

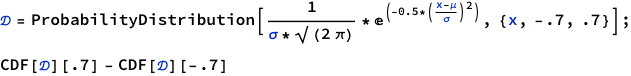
As you can observe, this approach is much better. Though it may not be as easy to understand what’s really going on under the hood, it is cleaner once you already have understood what’s going on. For example, if we were to start directly with ProbabilityDistribution, we would not know how 6x(1-x) is executed and plotted.